Architecture
See below the functinal principle and architecture of a stand alone cluster setup.
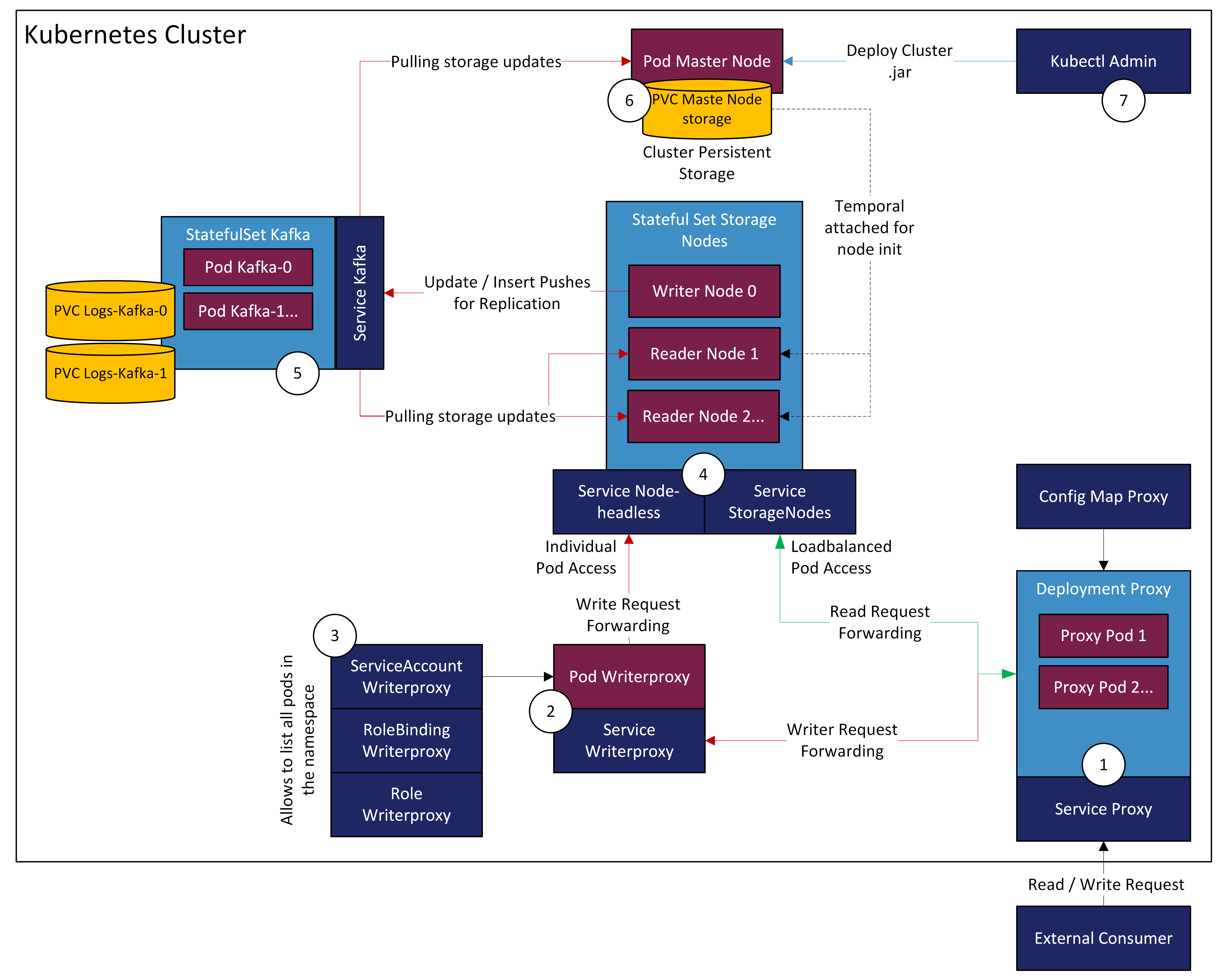
1. DNS Proxy:
-
First entrance point to the cluster. Kubernetes internal DNS entry proxy.
-
Forwards request wether it is a read or write request. This can be definded in the "Config-Map" see down below. Default routing is PUT, POST, PATCH and DELETE goes to writer proxy. All the other requests will be forwarded to reader nodes.
apiVersion: apps/v1
kind: Deployment
metadata:
name: proxy
spec:
replicas: 1
selector:
matchLabels:
microstream.one/cluster-component: proxy
template:
metadata:
labels:
microstream.one/cluster-component: proxy
spec:
imagePullSecrets: [ name: microstream-ocir-credentials ]
containers:
- name: nginx
image: nginx:1.27-alpine
ports:
- containerPort: 8080
name: http
protocol: TCP
volumeMounts:
- name: config
subPath: nginx.conf
mountPath: /etc/nginx/nginx.conf
volumes:
- name: config
configMap:
name: proxyapiVersion: v1
kind: ConfigMap
metadata:
name: proxy
data:
nginx.conf: |
# Automatically figure out how many workers (threads) should be started based on the on the available cpu cores
worker_processes auto;
events {
# The maximum number of simultaneous connections that can be opened by a worker process.
# Check allowed open file limits per process with: `ulimit -n`
# Most distros have a default limit of 1k
worker_connections 1000;
}
http {
# Disable access log to prevent spam
access_log off;
# Filter out HTTP 200-300 access logs. Keep others like HTTP 400 (user error) HTTP 500 (server error)
map $status $loggable {
~^[23] 0;
default 1;
}
proxy_http_version 1.1;
# The dns resolver inside the kubernetes cluster. If we don't add this nginx won't know how to resolve our subdomains like 'writerproxy'
resolver kube-dns.kube-system.svc.cluster.local;
# Map PUT|PATH|DELETE|POST requests to the writerproxy domain
# Any modifying request that the cluster receives should go through the writerproxy
# This node knows which storage node is the current writer and forwards the request to it
map $request_method $upstream_location {
PUT writerproxy.my-microstream-cluster.svc.cluster.local;
PATCH writerproxy.my-microstream-cluster.svc.cluster.local;
DELETE writerproxy.my-microstream-cluster.svc.cluster.local;
POST writerproxy.my-microstream-cluster.svc.cluster.local;
# Any other request can go to the node subdomain. This will go to a random storage node that the loadbalancer deems as sufficent.
default storagenode.my-microstream-cluster.svc.cluster.local;
}
server {
# Listen for incoming connections on port 8080. The proxy service resource specifies which port you actually have to call, but
# a good practise is to use 8080 inside the containers so we don't need to access the lower port number range
listen 8080;
location / {
# Set some proxy header information
proxy_set_header Host $proxy_host;
proxy_set_header Connection close;
# Select the correct subdomain and forward the request to it.
# Internally the cluster communicates via http. All the https traffic should come from the outside to a configured ingress
proxy_pass http://$upstream_location;
}
}
}apiVersion: v1
kind: Service
metadata:
name: proxy
spec:
selector:
microstream.one/cluster-component: proxy
ports:
- name: http
port: 80
targetPort: http2. Writerproxy:
-
Stores the current writer and elects after a possible pod crash or restart of the cluster.
apiVersion: v1
kind: Pod
metadata:
name: writerproxy
labels:
microstream.one/cluster-component: writerproxy
spec:
serviceAccountName: writerproxy
imagePullSecrets: [ name: microstream-ocir-credentials ]
securityContext:
fsGroup: 1000
containers:
- name: writerproxy
image: ocir.microstream.one/onprem/image/microstream-cluster-writer-proxy:1.10.0-SNAPSHOT
env:
- name: MICROSTREAM_PATH
value: '/microstream-cluster-controller/'
- name: WRITER_PROXY_LOG_LEVEL
value: TRACE
- name: ROOT_LOG_LEVEL
value: INFO
ports:
- name: http
containerPort: 8080
livenessProbe:
initialDelaySeconds: 3
timeoutSeconds: 3
failureThreshold: 5
httpGet:
path: /health
port: http
readinessProbe:
initialDelaySeconds: 3
timeoutSeconds: 3
failureThreshold: 5
httpGet:
path: /health/ready
port: http
startupProbe:
timeoutSeconds: 5
failureThreshold: 10
httpGet:
path: /health
port: httpapiVersion: v1
kind: Service
metadata:
name: writerproxy
spec:
ports:
- port: 80
targetPort: http
protocol: TCP
name: http
selector:
microstream.one/cluster-component: writerproxy3. Rolebinding
-
Create the writerproxy rbac resources. These give the writerproxy access to list all pods in the namespace. This is needed so the writerproxy knows what storagenodes are running.
apiVersion: v1
kind: ServiceAccount
metadata:
name: writerproxy
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: writerproxy
rules:
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
- watch
- list
- apiGroups:
- ""
resources:
- pods
verbs:
- list
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: writerproxy
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: writerproxy
subjects:
- kind: ServiceAccount
name: writerproxy4. Storage-Nodes (StatefullSet):
-
One Writer-Node for data manipulation requests
-
Multiple Reader-Nodes for reading requests
apiVersion: v1
kind: Service
metadata:
name: node-headless
spec:
clusterIP: None
type: ClusterIP
ports:
- name: http
port: 80
targetPort: http
selector:
microstream.one/cluster-component: storagenode
---
apiVersion: v1
kind: Service
metadata:
name: storagenode
spec:
ports:
- name: http
port: 80
targetPort: http
selector:
microstream.one/cluster-component: storagenodeapiVersion: apps/v1
kind: StatefulSet
metadata:
name: storagenode
spec:
podManagementPolicy: Parallel
replicas: 1
serviceName: node-headless
selector:
matchLabels:
microstream.one/cluster-component: storagenode
template:
metadata:
labels:
microstream.one/cluster-component: storagenode
app.kubernetes.io/component: node
spec:
imagePullSecrets: [ name: microstream-ocir-credentials ]
securityContext:
runAsNonRoot: true
fsGroupChangePolicy: OnRootMismatch
fsGroup: 10000
runAsUser: 10000
runAsGroup: 10000
initContainers:
- name: prepare-storagenode
image: curlimages/curl:8.11.1
command:
- sh
- -ce
- |
# Wait for the user rest service project to exist
echo "Waiting for user rest service jar (timeout=5min)..."
i=0
until [ -f /masternode/project/ready ]; do
sleep 1s
# Fail if we time out
if [ $i -gt 300 ]; then
echo "Timed out waiting for /masternode/project/ready to exist" >&2
exit 1
fi
i=$((i+1))
done
echo "Success!"
# Wait for masternode storage for 5 minutes
echo "Waiting for backup storage to exist (timeout=5min)..."
i=0
until [ -f /masternode/storage/PersistenceTypeDictionary.ptd -a -d /masternode/storage/channel_0 ]; do
sleep 1s
# Fail if we time out
if [ $i -gt 300 ]; then
echo "Timed out waiting for backup storage to exist" >&2
exit 1
fi
i=$((i+1))
done
echo "Success!"
# Clone the masternode storage as a starting point
echo "Trying to remove any residual storage files..."
rm -r /storage/storage && echo "Removed previous storage files" || echo "No residual storage files located"
rm /storage/offset && echo "Removed previous offset file" || echo "No residual storage offset located"
echo "Cloning the masternode storage..."
cp -r /masternode/storage /storage/storage
echo "Cloning the masternode offset file..."
cp /masternode/offset /storage/offset
echo "Cloning the user rest service project..."
cp -r /masternode/project /storage
echo "Success!"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ all ]
volumeMounts:
- name: masternode-storage
mountPath: /masternode
readOnly: true
- name: storage
mountPath: /storage
containers:
- name: storagenode
image: ocir.microstream.one/onprem/image/microstream-cluster-storage-node:1.10.0-SNAPSHOT
args: [ /storage/project/project.jar ]
workingDir: /storage
env:
- name: MSCNL_PROD_MODE
value: "true"
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: IS_BACKUP_NODE
value: "false"
- name: KAFKA_BOOTSTRAP_SERVERS
value: kafka-0.kafka:9092
- name: MSCNL_KAFKA_TOPIC_NAME
value: storage-data
- name: MSCNL_SECURE_KAFKA
value: "false"
- name: MSCNL_KAFKA_USERNAME
value: ""
- name: MSCNL_KAFKA_PASSWORD
value: ""
- name: MICROSTREAM_PATH
value: "/microstream-cluster-controller/"
- name: STORAGE_LIMIT_GB
value: "20G"
- name: STORAGE_LIMIT_CHECKER_PERCENT
value: "95"
- name: STORAGE_LIMIT_CHECKER_INTERVAL_MINUTES
value: "60"
ports:
- name: http
containerPort: 8080
# Restart the pod if container is not responsive at all
livenessProbe:
timeoutSeconds: 5
failureThreshold: 5
httpGet:
path: /microstream-cluster-controller/microstream-health
port: http
# Remove the pod from being ready if we fail to check
readinessProbe:
timeoutSeconds: 4
failureThreshold: 3
httpGet:
path: /microstream-cluster-controller/microstream-health/ready
port: http
# Give the container ~50 seconds to fully start up
startupProbe:
timeoutSeconds: 5
failureThreshold: 10
httpGet:
path: /microstream-cluster-controller/microstream-health
port: http
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ all ]
volumeMounts:
- name: storage
mountPath: /storage
volumes:
- name: user-rest-service
emptyDir:
- name: storage
emptyDir:
- name: masternode-storage
persistentVolumeClaim:
claimName: masternode-storage
readOnly: true5. KAFKA replication queue
-
Distributes data from the writer storage node to other storage nodes and the master node
apiVersion: v1
kind: Service
metadata:
name: kafka
spec:
ports:
- name: plaintext
targetPort: plaintext
port: 9092
- name: controller
targetPort: controller
port: 9093
selector:
microstream.one/cluster-component: kafkaapiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
spec:
serviceName: kafka
replicas: 1
podManagementPolicy: Parallel
selector:
matchLabels:
microstream.one/cluster-component: kafka
template:
metadata:
labels:
microstream.one/cluster-component: kafka
spec:
imagePullSecrets: [ name: microstream-ocir-credentials ]
containers:
- name: kafka
image: ocir.microstream.one/onprem/image/microstream-cluster-kafka:1.10.0-SNAPSHOT
ports:
- name: plaintext
containerPort: 9092
- name: controller
containerPort: 9093
env:
# Configurations are automatically parsed from envars prefixed with KAFKA_CFG
# The keys are transformed from snake case to dotted lowercase
# Used for kafka node id and ADVERTISED_LISTENER generation. The bootstrap script takes the id part (for kafka-0 it would be 0)
# and sets the NODE_ID to that value. For ADVERTISED_LISTENER it will simply replace %'s with the pod name
# e.g. CLIENT://%.kafka:9092 = CLIENT://kafka-0.kafka:9092
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
# UUID identifying this kafka cluster
- name: KAFKA_CFG_CLUSTER_ID
value: sZDP3FUBQGWfNSEFG1Y-jA
# Server Basics
- name: KAFKA_CFG_PROCESS_ROLES
value: broker,controller
- name: KAFKA_CFG_CONTROLLER_QUORUM_BOOTSTRAP_SERVERS
value: localhost:9093
# Server Socket Settings
- name: KAFKA_CFG_INTER_BROKER_LISTENER_NAME
value: PLAINTEXT
- name: KAFKA_CFG_CONTROLLER_LISTENER_NAMES
value: CONTROLLER
- name: KAFKA_CFG_LISTENERS
value: PLAINTEXT://:9092,CONTROLLER://:9093
- name: ADVERTISED_LISTENERS_TEMPLATE
value: PLAINTEXT://%.kafka:9092,CONTROLLER://%.kafka:9093
- name: KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP
value: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# Should be set appropriately with how many cores are available for multithreading etc.
- name: KAFKA_CFG_NUM_NETWORK_THREADS
value: "3"
# Should be set appropriately with how many cores are available for multithreading etc.
- name: KAFKA_CFG_NUM_IO_THREADS
value: "8"
# Log Basics
- name: KAFKA_CFG_LOG_DIR
value: /mnt/kafka/logs
- name: KAFKA_CFG_NUM_PARTITIONS
value: "1"
# Internal Topic Settings
- name: KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR
value: "1"
- name: KAFKA_LOG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_CONFIG_STORAGE_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_OFFSET_STORAGE_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_STATUS_STORAGE_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_ERRORS_DEADLETTERQUEUE_TOPIC_REPLICATION_FACTOR
value: "1"
- name: KAFKA_CFG_REPLICATION_FACTOR
value: "1"
# Log Retention Policy
# These need to be kept until we are sure that the masternode has consumed the messages
# because new storage nodes will clone the masternode storage, we effectively don't need messages older than the
# current masternode state.
- name: KAFKA_CFG_LOG_RETENTION_HOURS
# 336 hours = 2 weeks
value: "336"
volumeMounts:
- name: logs
mountPath: /mnt/kafka
volumeClaimTemplates:
- metadata:
name: logs
spec:
accessModes: [ ReadWriteOnce ]
resources:
requests:
storage: 20G6. Master-Node:
-
Create the master node. This holds the storage in a persistent volume and provides it to newly started storage nodes.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: masternode-storage
spec:
# Needs to be read-write-many so every storage node can attach and clone the storage as a starting point
accessModes: [ ReadWriteMany ]
resources:
requests:
storage: 20GapiVersion: v1
kind: Pod
metadata:
name: masternode
spec:
imagePullSecrets: [ name: microstream-ocir-credentials ]
securityContext:
runAsNonRoot: true
fsGroupChangePolicy: OnRootMismatch
fsGroup: 10000
runAsUser: 10000
runAsGroup: 10000
initContainers:
- name: prepare-masternode
image: curlimages/curl:8.11.1
command:
- sh
- -ce
- |
# Wait for the user rest service project to exist
# You can upload the jar like this:
# `kubectl cp -c prepare-masternode /path/to/jar masternode:/storage/project/project.jar`
# If you have a libs folder as well you can copy it with
# `kubectl cp -c prepare-masternode /path/to/libs masternode:/storage/project`
# When you are done create the ready flag with
# `kubectl exec -ti -c prepare-masternode pod/masternode -- touch /storage/project/ready`
mkdir -p /storage/project
echo "Waiting for user rest service jar (timeout=5min)..."
i=0
until [ -f /storage/project/ready ]; do
sleep 1s
# Fail if we time out
if [ $i -gt 300 ]; then
echo "Timed out waiting for /storage/project/ready to exist" >&2
exit 1
fi
i=$((i+1))
done
echo "Success!"
# Check for kafka ready flag for 5 minutes
echo "Waiting for kafka to be ready (timeout=5min)..."
i=0
until nc -z -w5 kafka 9092; do
sleep 1s
# Fail if we time out
if [ $i -gt 300 ]; then
echo "Timed out waiting for kafka to be ready" >&2
exit 1
fi
i=$((i+1))
done
echo "Success!"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ all ]
volumeMounts:
- name: storage
mountPath: /storage
containers:
- name: masternode
image: ocir.microstream.one/onprem/image/microstream-cluster-storage-node:1.10.0-SNAPSHOT
workingDir: /storage
args: [ "/storage/project/project.jar" ]
env:
- name: MSCNL_PROD_MODE
value: "true"
- name: KAFKA_BOOTSTRAP_SERVERS
value: kafka-0.kafka:9092
- name: MSCNL_KAFKA_TOPIC_NAME
value: storage-data
- name: MSCNL_SECURE_KAFKA
value: "false"
- name: MSCNL_KAFKA_USERNAME
value: ""
- name: MSCNL_KAFKA_PASSWORD
value: ""
# Keep Spring Boot (if used in the user rest service) from initializing the user controllers which might lead to NPEs
- name: SPRING_MAIN_LAZY-INITIALIZATION
value: "true"
- name: IS_BACKUP_NODE
value: "true"
- name: BACKUP_PROXY_SERVICE_URL
value: external-resource-proxy
ports:
- name: http
containerPort: 8080
# Restart the pod if container is not responsive at all
livenessProbe:
timeoutSeconds: 5
failureThreshold: 5
httpGet:
path: /microstream-cluster-controller/microstream-health
port: http
# Remove the pod from being ready if we fail to check
readinessProbe:
timeoutSeconds: 4
failureThreshold: 3
httpGet:
path: /microstream-cluster-controller/microstream-health/ready
port: http
# Give the container ~50 seconds to fully start up
startupProbe:
timeoutSeconds: 5
failureThreshold: 10
httpGet:
path: /microstream-cluster-controller/microstream-health
port: http
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ all ]
volumeMounts:
- name: storage
mountPath: /storage
volumes:
- name: storage
persistentVolumeClaim:
claimName: masternode-storage