Replicated Hibernate Second-Level Cache
The EclipseStore Hibernate Second-Level Cache can be extended with cache replication when deployed in an Eclipse Data Grid cluster. In a clustered environment, each application node maintains its own local cache. Without replication, cache invalidation on one node would not propagate to other nodes, leading to stale data. The clustered cache module solves this by using Apache Kafka as a messaging backbone to replicate cache events across all nodes.
For the basic, non-replicated Hibernate Second-Level Cache setup, see the EclipseStore documentation.
A full working demo application is available at cluster-hibernate-cache-demo.
How it works
Each application node runs its own EclipseStore-backed Hibernate cache. When a cache entry is created, updated or evicted on one node, the change event is published to a Kafka topic. All other nodes consume these events and update their local caches accordingly, ensuring consistency across the cluster.
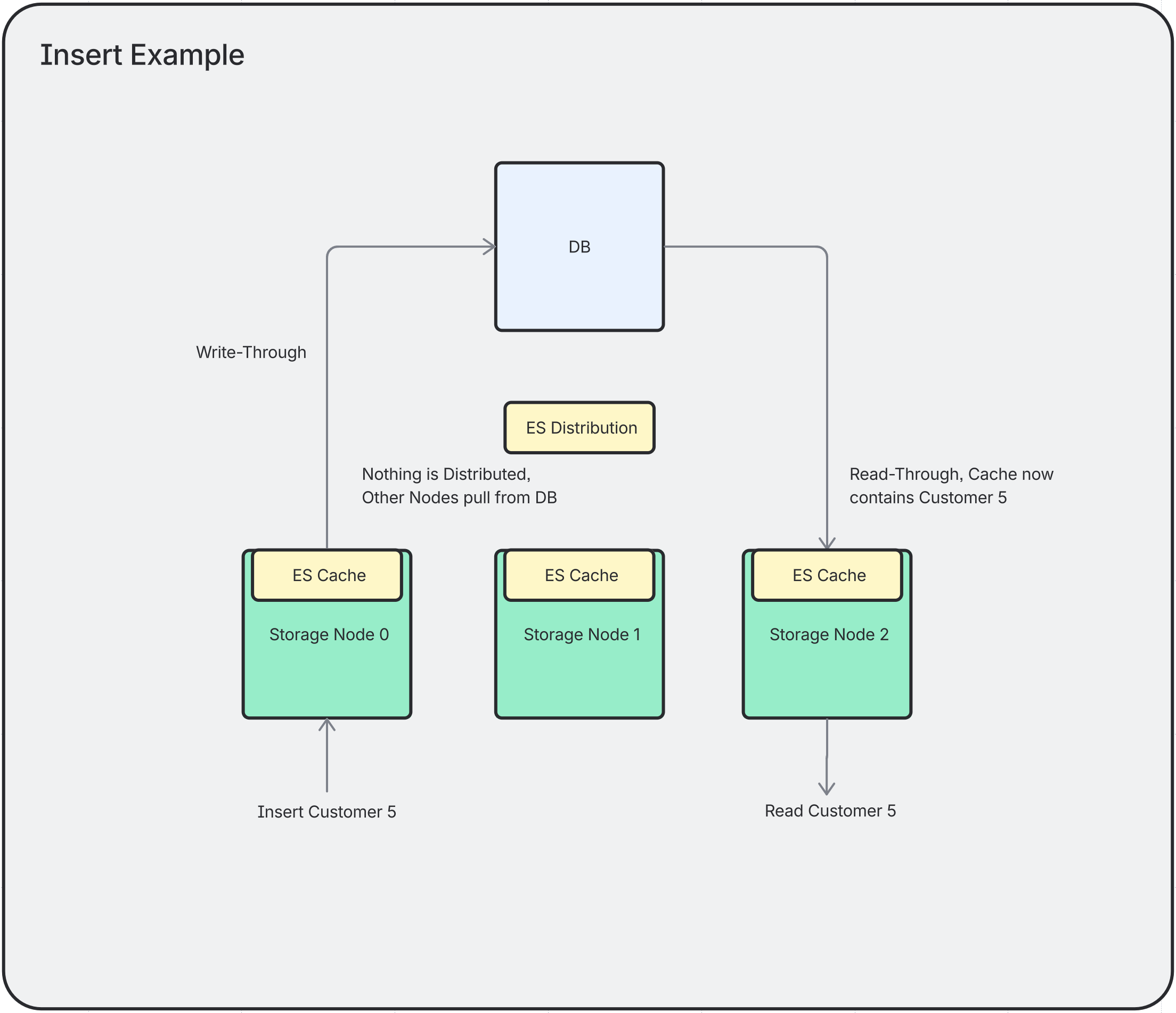
Insert
When a new entity is persisted, it is added to the local cache and the insert event is replicated to all other nodes via Kafka.
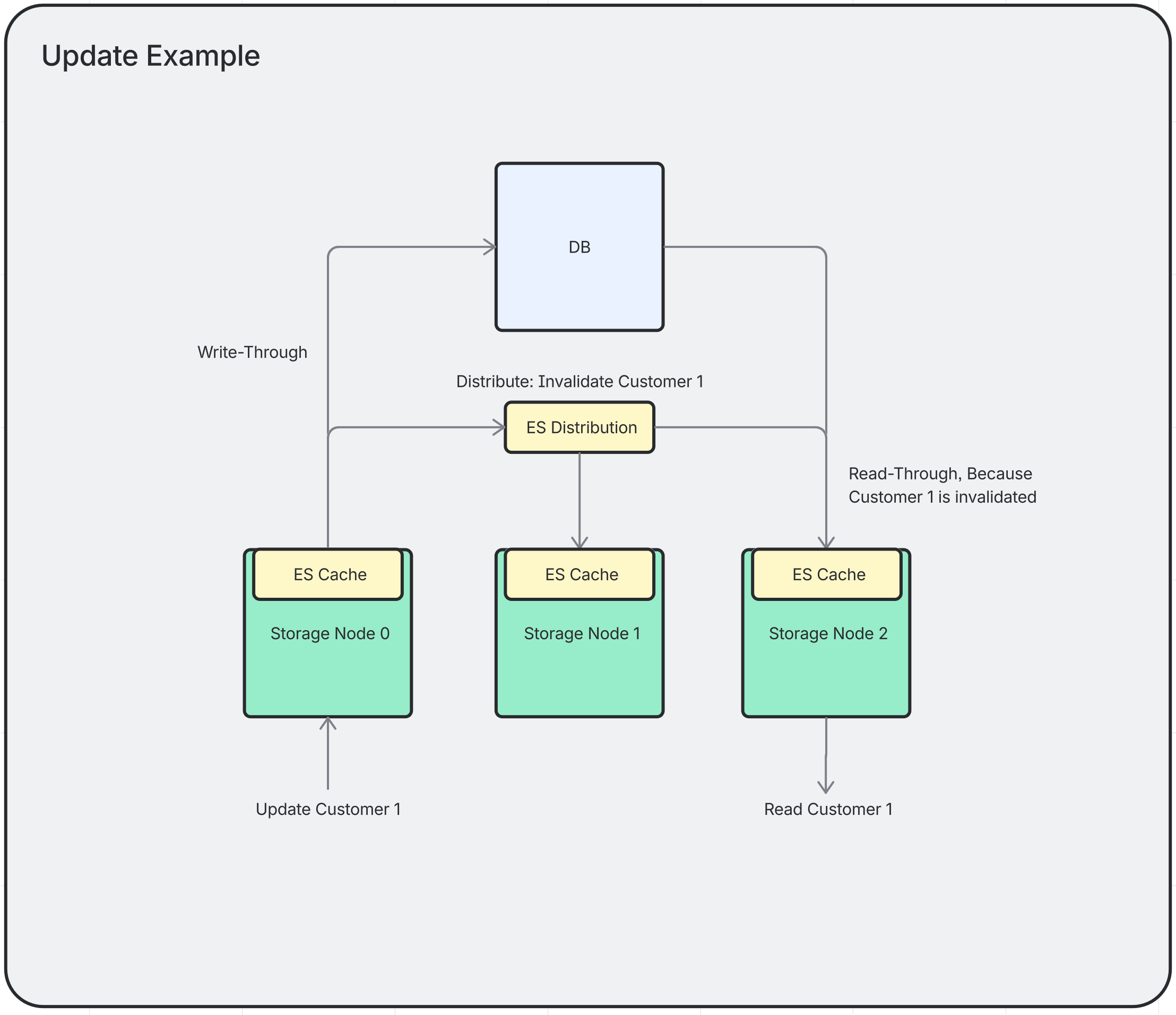
Update
When an entity is updated, the local cache entry is invalidated and the update event is propagated to all other nodes, which also invalidate their cached copy.
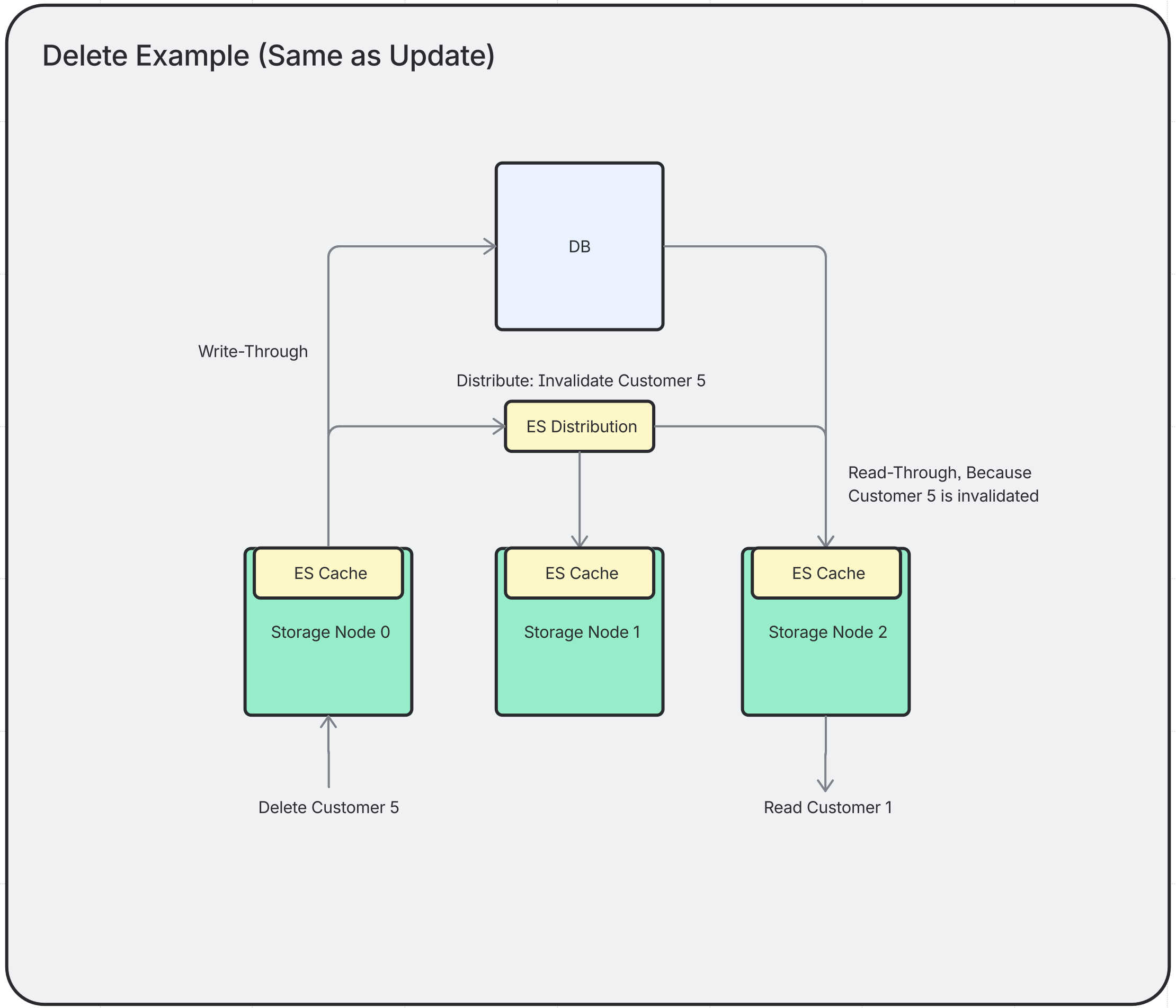
Delete
When an entity is deleted, it is removed from the local cache and the delete event is sent to all other nodes to evict the entry.
Cache Invalidation Flow
The following example illustrates how the query cache is kept consistent across nodes when an entity is updated:
-
A user sends an update book request that reaches Server 1.
-
Server 1 executes the update query against the database.
-
Hibernate updates its local
update-timestamps-regioncache with a new entry: the affected table name mapped to the current unix timestamp. -
This cache update emits an event that triggers the Kafka sender.
-
The sender publishes a message to the Kafka server containing the table name and the new update timestamp.
-
All other cache servers poll Kafka for new messages and receive the update.
-
Each server inserts the new table update timestamp into its own
update-timestamps-regioncache. -
When the next find all books request arrives:
-
If it reaches Server 1, the result is served directly from the query cache (the cache is already up to date).
-
If it reaches Server 2, Hibernate compares the cached query result timestamp against the
update-timestamps-region. Since the table was updated after the cached query result was stored, the query cache entry is considered stale. Server 2 re-executes the query against the database and caches the fresh result.
-